Building Enterprise AI Agents with Copilot Studio and Azure OpenAI
Table of contents
- Key Takeaways
- From Simple Chatbots to Autonomous Agentic AI
- How Advanced RAG Works in Copilot Studio
- Step 1: Ingestion and Chunking Layouts
- Step 2: The Hybrid Retrieval Strategy
- Grounding Agents inside Microsoft Dataverse
- Engineering the Enterprise Knowledge Graph:
- Enterprise Use Cases
- 1. Procurement and Supply Chain Automation
- 2. Underwriting and Claims Processing (Insurance & FinTech)
- 3. Customer Support with Live CRM Integration
- Data Isolation and Security
- Your Corporate Trust Boundaries:
- Operational Realities in Production
- 1. Retrieval Decay and Semantic Drift
- 2. The Cost Dynamics and the "Token Tax"
- 3. When Low-Code Hits the Ceiling
- 4. Preserving the Human-in-the-Loop Boundary
- The Enterprise AI Readiness Checklist
- Frequently Asked Questions
- How do we prevent our AI agents from surfacing outdated or stale corporate information?
- What is the single biggest "hidden cost" when running an enterprise RAG system?
- Does grounding an AI agent inside Copilot Studio automatically solve our data debt?
- When should our organization outgrow Copilot Studio and move to custom code?
- How does Microsoft Dataverse ensure our AI agents respect internal security boundaries?
- How do hybrid cloud states impact RAG performance during a migration?
- Build Secure AI Architectures with Emerline
Let’s be realistic: spinning up a quick Retrieval-Augmented Generation (RAG) prototype in Copilot Studio takes about twenty minutes, and it always looks flawless during a Friday afternoon demo. The real headache begins on Monday morning when you expose that demo to the messiness of actual enterprise data - shifting user permissions, massive legacy databases, and fluid, undocumented document updates.
Suddenly, your "intelligent assistant" is either hallucinating, bleeding thousands of dollars in unexpected token costs, or worse, accidentally exposing restricted payroll data to an unauthorized user group.
Building a production-grade AI agent isn't about choosing the biggest LLM; it's about engineering a secure, predictable trust boundary around it. As a certified Microsoft Solutions Partner, Emerline skips the theoretical AI hype and dives straight into the real-world architecture required to build autonomous, data-isolated agents that actually work in production.
Key Takeaways
- The Blueprint for Autonomy: Move past shallow keyword chatbots by combining multi-stage Reciprocal Rank Fusion (RRF) with vector semantic search to build context-aware, autonomous agents.
- Zero-Leakage Environments: Insulate corporate intellectual property by utilizing Azure OpenAI Service, guaranteeing that zero enterprise data, prompts, or transaction logs are ever used for public model training.
- Dynamic Data Grounding: Connect your orchestration layer natively with Microsoft Dataverse, inheriting your existing enterprise Role-Based Access Control (RBAC) down to the individual row and column.
- Eradicating Semantic Drift: Combat retrieval quality decay over time by implementing automated incremental re-indexing pipelines, metadata-aware chunk expiration, and data freshness scoring.
- Platform Engineering Shift: Maximize Day 2 operational velocity by building an Internal Developer Platform (IDP) and providing pre-approved "Golden Paths" to slash developer cognitive load.
From Simple Chatbots to Autonomous Agentic AI
Today, the era of basic, hardcoded Q&A chatbots is over. If your automated assistant can only respond to rigid keyword triggers, it’s failing your users. Modern enterprises now demand Agentic AI - autonomous intelligent agents capable of parsing messy natural language, dynamically orchestrating their own reasoning loops, and interacting directly with transactional backends.
But here is the catch: running autonomous agents in regulated sectors is a high-stakes balancing act. You need absolute factual grounding, and you cannot afford to let proprietary corporate data leak into public model pools.
To cross this chasm, enterprise architects are shifting away from basic out-of-the-box setups toward Advanced RAG (Retrieval-Augmented Generation) orchestrated within Microsoft Copilot Studio. By decoupling LLM reasoning from public training data and grounding your models strictly within isolated corporate repositories, you can build self-contained, highly secure AI agents that eliminate data leaks while systematically stamping out hallucinations. As a certified Microsoft Solutions Partner, Emerline delivers development through specialized Microsoft Copilot Studio services to architect these exact trust boundaries for global organizations.
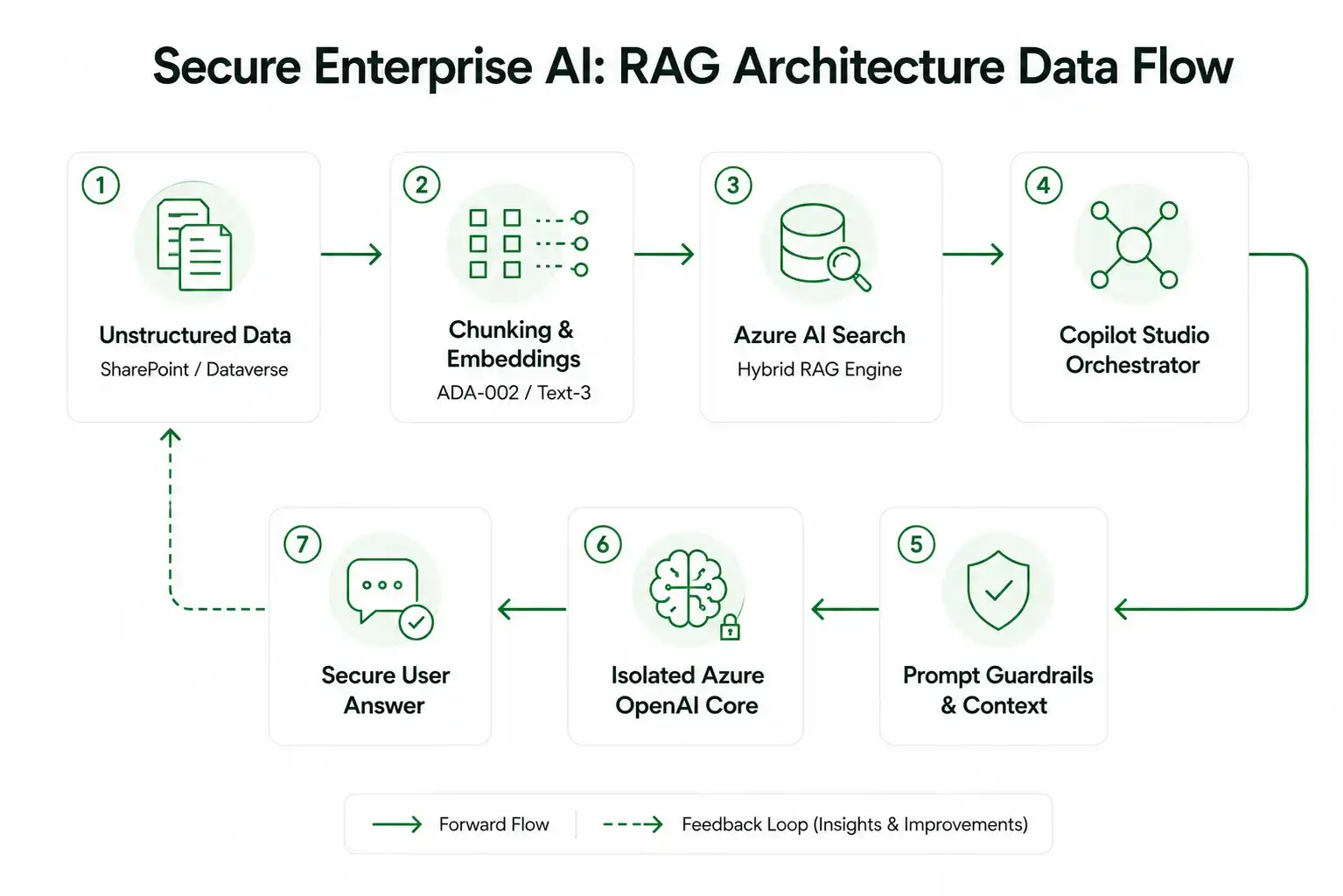
How Advanced RAG Works in Copilot Studio
A production-grade RAG pipeline bypasses the limitations of shallow keyword matching by converting your enterprise documentation into high-dimensional vector embeddings.
Step 1: Ingestion and Chunking Layouts
The quality of an agent's response is completely dependent on how you slice your ingestion layer. Shoving massive, multi-page PDFs down an LLM’s throat leads to context dilution. Instead, documents must be broken down into clean, semantic chunks (typically 250 to 500 tokens) using overlapping boundaries (10–20% overlap). This overlap ensures that critical contextual transitions across paragraphs don't get clipped during parsing.
These text fragments are processed via advanced embedding models, such as Azure OpenAI’s text-embedding-3-large, to generate dense vector representations that capture the underlying business intent of the data.
Step 2: The Hybrid Retrieval Strategy
Copilot Studio hooks natively into Azure AI Search to execute a dual-engine lookup strategy. When an internal user asks a complex question, the system fires two parallel search processes:
- Keyword Retrieval (BM25): To pinpoint exact alphanumeric product codes, compliance clauses, and highly specific industry nomenclature.
- Vector Semantic Search: To extract the actual meaning behind the query, even if the user uses completely different phrasing or synonyms.
The search engine then applies a Reciprocal Rank Fusion (RRF) algorithm backed by neural re-ranking models. This ensures that only the top-N most contextually precise data fragments land in the LLM's prompt window, cutting out noise and lowering your token costs.
Many development teams make the mistake of leaving their primary database on-premise while hosting their AI compute layer in the cloud. This triggers a massive performance penalty. Every single user query forces a data round-trip that introduces severe latency lag. If you are building high-concurrency RAG systems, resolve your data debt first by executing a comprehensive enterprise cloud migration and refactoring program to establish a low-latency cloud landing zone.
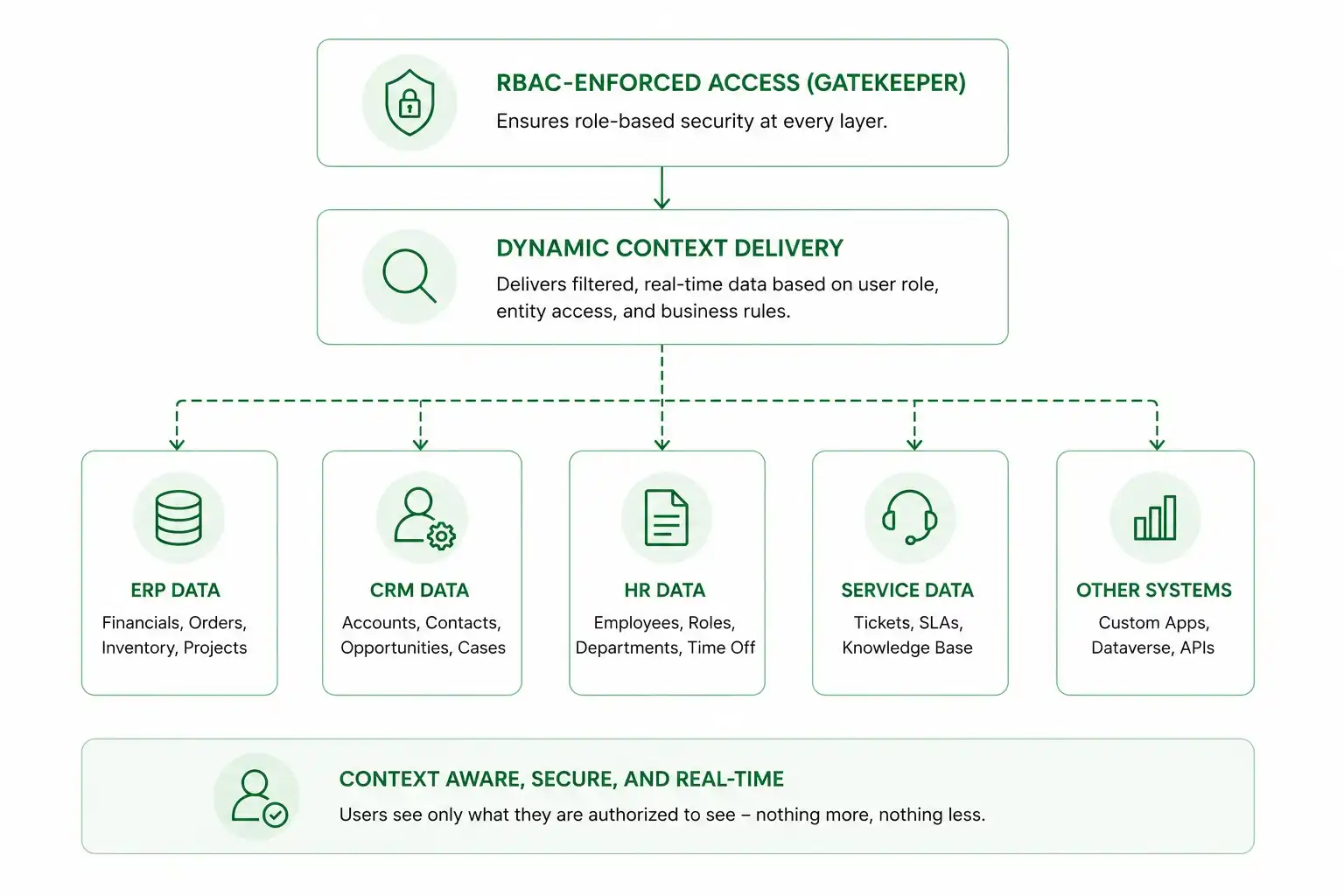
Grounding Agents inside Microsoft Dataverse
For real-world transactional workloads, grounding AI agents inside static PDF manuals is a dead end. Production-grade agents need to know what is happening in your business right now. They require secure access to relational business records, real-time inventory systems, and active customer pipelines. This is why connecting your agents to Microsoft Dataverse is a game-changer.
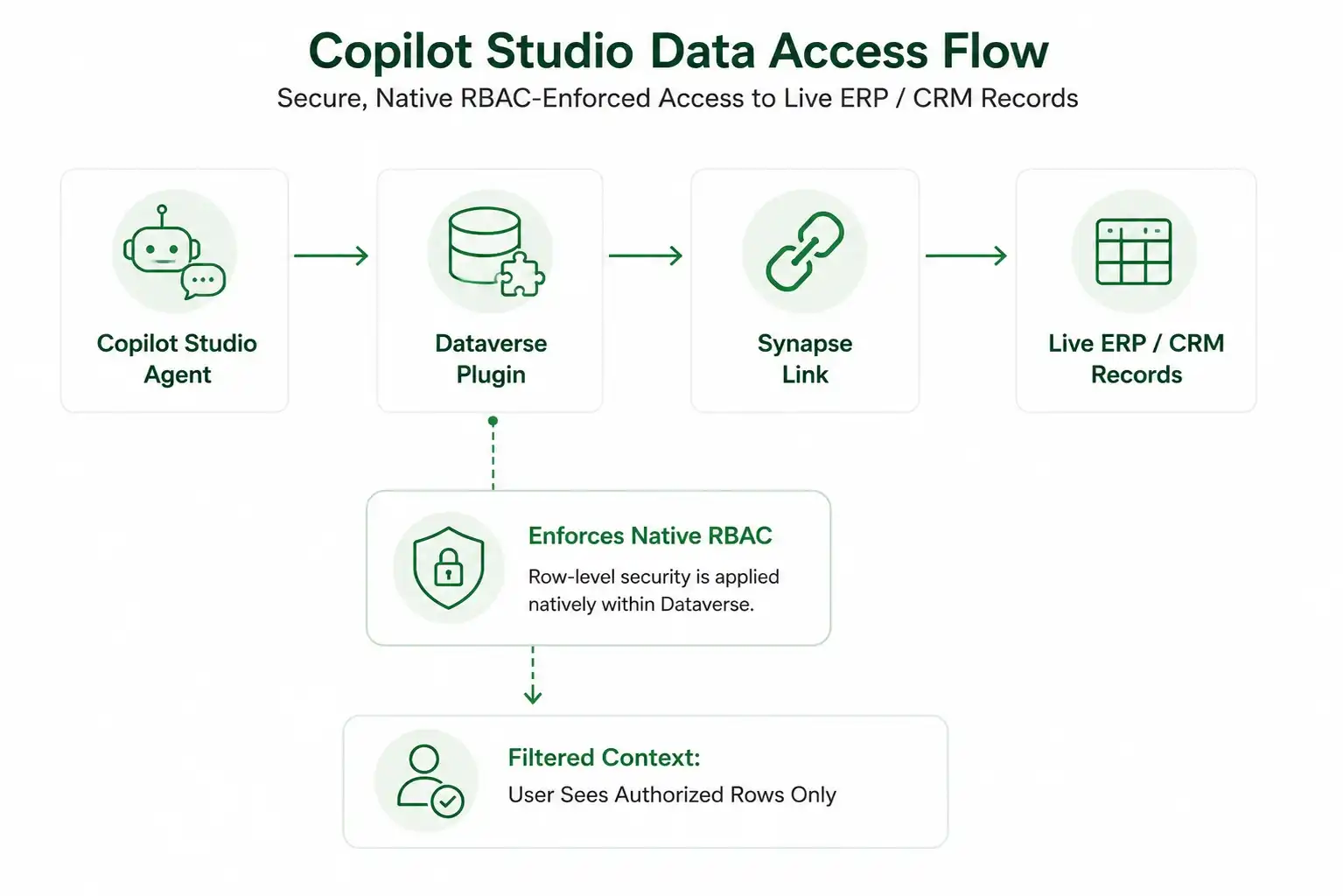
Engineering the Enterprise Knowledge Graph:
- Dataverse Tools and Connectors: Copilot Studio utilizes native Power Platform connectors and Dataverse tools to dynamically translate natural language intents into secure relational queries, fetching live customer records or inventory telemetry on demand.
- Inherited Role-Based Access Control (RBAC): Copilot Studio agents respect your Dataverse security configuration down to the individual row and column. When configured to use end-user authentication, the agent inherits the logged-in user's Dataverse RBAC permissions. If a customer support representative is not authorized to access a client's billing data in the CRM system, the Copilot Studio agent cannot retrieve that information during its execution flow. This helps ensure that existing security boundaries remain consistently enforced across AI-driven interactions.
- Real-Time Analytical Sync: By leveraging native Synapse links, AI agents can run RAG logic against freshly updated transactional data rather than relying on outdated, batch-processed data dumps.
Enterprise Use Cases
Deploying agents within a governed architecture transforms data pools into real-time performance drivers. Below is how cross-domain businesses leverage Copilot Studio and RAG to automate execution paths safely:
1. Procurement and Supply Chain Automation
The Blueprint: Agents connect directly to active supplier contracts (stored in SharePoint) and live ERP inventory tables (grounded via Dataverse).
The Execution: A supply chain manager asks: "Are we covered for a 20% delay in semiconductor deliveries from our primary East Asian vendor?" The agent cross-references the specific force majeure clauses in the vendor's active PDF contract with current stock buffers in the ERP, calculating the exact operational buffer runway without manual data compilation.
2. Underwriting and Claims Processing (Insurance & FinTech)
The Blueprint: Automated prompt routing layers match incoming claims against localized regulatory frameworks and historical customer risk profiles.
The Execution: When a complex claim is filed, the agent parses the unstructured damage report, matches it against the customer's policy restrictions, and runs a compliance check against active underwriting guidelines. It either highlights policy anomalies for human adjusters or auto-approves standard claims within predefined thresholds.
3. Customer Support with Live CRM Integration
The Blueprint: Copilot Studio handles customer-facing validation and entry routing, passing authentication tokens securely to Dataverse CRM fields.
The Execution: Instead of providing static FAQ answers, the agent accesses the user’s order history, active shipping telemetry, and open support tickets. It can independently re-route a delayed package, initiate a refund under strict corporate parameters, or smoothly hand off accounts to human managers along with a compiled interaction summary.
Data Isolation and Security
The number one objection from security compliance officers regarding generative AI is the risk of trade secrets or customer PII slipping into public training datasets. Copilot Studio paired with Azure OpenAI helps keep corporate data within your Microsoft tenant and governed by existing security controls.
Your Corporate Trust Boundaries:
- Zero Public Model Training: Microsoft explicitly guarantees that your prompts, retrieved data fragments, transactional logs, and user histories are never used to train or fine-tune public LLMs. Your corporate knowledge remains exclusively yours.
- Customer-Managed Encryption Keys (CMK): Data stored in Dataverse or cached within vector indexes is encrypted at rest using AES-256 encryption, with encryption keys managed by your organization through Azure Key Vault.
- Geofenced Data Sovereignty: Your deployment landing zones are locked to specific regions (for example, East US, West Europe, or Spain Central). This guarantees that model inference and token processing stay strictly within defined geographic borders, comfortably satisfying strict regulatory frameworks like GDPR and CCPA.
Operational Realities in Production
Let’s step away from the marketing slides: a RAG system that runs flawlessly during a controlled Friday demo can easily degrade when exposed to thousands of real-world corporate users. Scale introduces brutal data complexities that require proactive engineering.
1. Retrieval Decay and Semantic Drift
Documents evolve, compliance rules shift, and product catalogs are updated daily. Over time, your older vector embeddings begin to suffer from semantic drift-they gradually lose alignment with the current state of your business operations.
To prevent your agents from confidently serving up obsolete procedures, you need to transition to a dynamic data lifecycle model. To deeply understand how continuous infrastructure tuning impacts your bottom line and prevents systemic resource waste, explore our comprehensive guide to the benefits of cloud computing.
2. The Cost Dynamics and the "Token Tax"
Here is an uncomfortable truth about RAG architecture: higher accuracy costs more money. To squeeze out hallucinations, you need larger chunks, multi-stage re-ranking algorithms, and denser vector indices.
While this precision engineering ensures highly reliable answers, it drastically expands the size of the prompt context window sent to the LLM. For high-volume internal systems, this means a massive surge in Azure OpenAI token consumption, heavy compute load on your search nodes, and sudden latency spikes during shift changes.
Don't wait for your first monthly cloud bill to discover that your AI agents are burning capital. Implement a strict FinOps governance framework from day one. Use Infrastructure as Code to automate tagging on every compute resource, and leverage Azure Spot Virtual Machines for compute-intensive background tasks such as vector reindexing pipelines. This simple architectural guardrail can slash your background compute costs by up to 90%.
3. When Low-Code Hits the Ceiling
Copilot Studio is fantastic for high-velocity deployments within the Microsoft ecosystem. However, low-code graphical orchestration inevitably hits a wall when your business logic demands highly custom reasoning chains, deterministic workflow paths, or fine-grained prompt routing.
When systems outgrow basic templates, the smartest enterprise pattern is a hybrid orchestration model. We design the architecture so that Copilot Studio handles the frontend user interaction, authentication, and compliance boundaries, while custom middleware hosted in Azure Kubernetes Service (AKS) or built using Semantic Kernel and LangGraph controls the underlying retrieval mechanics and business execution paths.
4. Preserving the Human-in-the-Loop Boundary
No matter how advanced your RAG pipeline is, generative models should never operate on total, unmonitored autonomy in risk-sensitive sectors like healthcare, insurance, or corporate finance.
Production-grade AI engineering isn't about fully replacing your workforce; it’s about controlled human augmentation. The most successful enterprise AI tools are designed as accelerators that automate repetitive data parsing, while leaving clear, auditable human checkpoints for final business execution.
The Enterprise AI Readiness Checklist
Before you invest your innovation budget into large-scale Copilot initiatives, you must audit your surrounding information architecture. Data fragmentation, rather than model capability, is one of the most common reasons corporate AI projects struggle to deliver value.
Ask your technical leadership these six questions:
- Knowledge Centralization: Is your data consolidated in accessible cloud repositories, or is it trapped in disconnected file silos?
- Permission Mapping: Are document-level access permissions strictly aligned with your corporate Active Directory to prevent internal data leaks?
- Data Integrity Ownership: Do you have dedicated data teams responsible for cleaning and validating the accuracy of your source databases?
- Index Stability: Are your primary data sources stable enough to undergo continuous vector indexing without breaking pipelines?
- Boundary Verification: Can your security teams independently audit and test AI data extraction paths?
- Regression Frameworks: Do you have an automated pipeline for continuous prompt engineering optimization and testing?
If your current information architecture feels unorganized, your AI outputs will mirror that chaos. Resolving this operational debt is the mandatory first step toward automation. To map out how your core operational systems will scale alongside these intelligent data layers, read our deep-dive tutorial on the fundamentals of the Microsoft ecosystem.
Frequently Asked Questions
How do we prevent our AI agents from surfacing outdated or stale corporate information?
This is the classic battle against semantic drift. If your documentation changes daily, static vector embeddings will fail. To keep your agents accurate, you must implement a dynamic data lifecycle strategy. At Emerline, we tackle this by setting up automated incremental re-indexing pipelines within Azure AI Search to crawl modifications in real time. We also build metadata-aware chunk expiration policies directly into the code and implement document freshness scoring, ensuring the LLM heavily prioritizes data updated within the last 90 days. For a deeper look at managing continuous data lifecycles and infrastructure maintenance updates, read our comprehensive guide to the benefits of cloud computing.
What is the single biggest "hidden cost" when running an enterprise RAG system?
The largest hidden cost is what we call the "Token Tax." To eliminate hallucinations, engineers naturally use larger chunk sizes, denser vector indices, and multi-stage re-ranking layers (like combining BM25 with neural re-rankers). While this precision engineering makes the AI incredibly reliable, it drastically swells the size of the prompt context window sent to the LLM. Every single query then triggers massive token consumption, high compute loads on your search nodes, and increased inference latency. To scale without bleeding capital, you must establish strict token governance and run a continuous FinOps budget-tracking process from day one.
Does grounding an AI agent inside Copilot Studio automatically solve our data debt?
Absolutely not. Moving messy, unorganized corporate data into an AI tool simply gives you an automated, more expensive mess. AI models (LLMs and RAG) require high-speed access to clean, well-structured, and vectorized data. If your data is trapped inside siloed legacy databases or poorly managed file repositories, the AI will either hallucinate or fail to retrieve the context entirely. True transformation requires a "Data-First" modernization strategy. Before deploying agents, you need to clean, label, and optimize your information architecture. To see how to properly structure your data layers and align your core operational systems for AI readiness, browse our ultimate guide to the fundamentals of the Microsoft ecosystem.
When should our organization outgrow Copilot Studio and move to custom code?
Copilot Studio is unparalleled for rapid, low-code deployments natively integrated with Office 365, SharePoint, and Dataverse. However, you will hit a functional ceiling the moment your business logic requires highly complex reasoning chains, custom state machines, or deterministic workflow routing. When this happens, you don't have to abandon Copilot Studio entirely. The industry-standard architecture is a hybrid orchestration model. We design systems where Copilot Studio serves as the secure, user-facing interaction and authentication layer, while a custom middleware backend hosted in Azure Kubernetes Service (AKS) or built via Semantic Kernel and LangGraph handles the heavy retrieval mechanics and core business execution.
How does Microsoft Dataverse ensure our AI agents respect internal security boundaries?
Dataverse does the heavy lifting here by automatically passing your existing enterprise security permissions directly down to the AI agent. Through native Power Platform connectors and Dataverse plugins, natural language prompts are translated into secure relational queries. Because Dataverse enforces strict Role-Based Access Control (RBAC) down to the individual row and column level, an AI agent cannot see, read, or pull a data fragment that the active user isn't explicitly authorized to access in your CRM or ERP. This ensures complete data isolation between departments without needing to build custom security filters from scratch.
How do hybrid cloud states impact RAG performance during a migration?
A hybrid state-where your AI orchestration lives in the cloud but your primary databases remain on-premise-is the ultimate performance bottleneck. Running queries across a hybrid network forces massive data round-trips that introduce crippling latency and drive up data egress fees. If your users require real-time, low-latency responses from their AI assistants, you cannot afford to leave your data stranded on old physical hardware. You must clear your technical debt early by migrating your legacy workloads into optimized cloud environments. Explore how to safely transition your infrastructure without operational downtime by utilizing our enterprise cloud migration and refactoring services.
Build Secure AI Architectures with Emerline
Deploying autonomous, compliant AI agents within an enterprise infrastructure requires an engineering partner with deep cloud-native experience, data modeling mastery, and advanced security certifications. As a certified Microsoft Solutions Partner, Emerline specializes in modernizing legacy technical debt, building secure RAG data meshes, and deploying scalable Agentic AI workflows tailored to your industry's exact compliance constraints.
Contact our AI and Data engineers to schedule an AI Readiness Evaluation, optimize your data infrastructure, and deploy secure autonomous agents inside your corporate ecosystem.
Disclaimer & Limitation of Liability: The architecture layouts, security frameworks, and technical metrics presented in this guide are based on industry evaluations for informational purposes only. They do not constitute formal technical, legal, or compliance advice. Emerline assumes no liability or responsibility for any business decisions, infrastructure implementations, unexpected compute costs, or third-party data governance outcomes resulting from the use of this material.
Published on Apr 1, 2026





